
Okay, so today I’m gonna walk you through my little experiment with scraping data from Chinese short video platforms, Douyin (TikTok’s Chinese version) and Kuaishou, and then trying to analyze the trends with a South China focus. It was a bit of a messy journey, but hey, that’s how you learn, right?
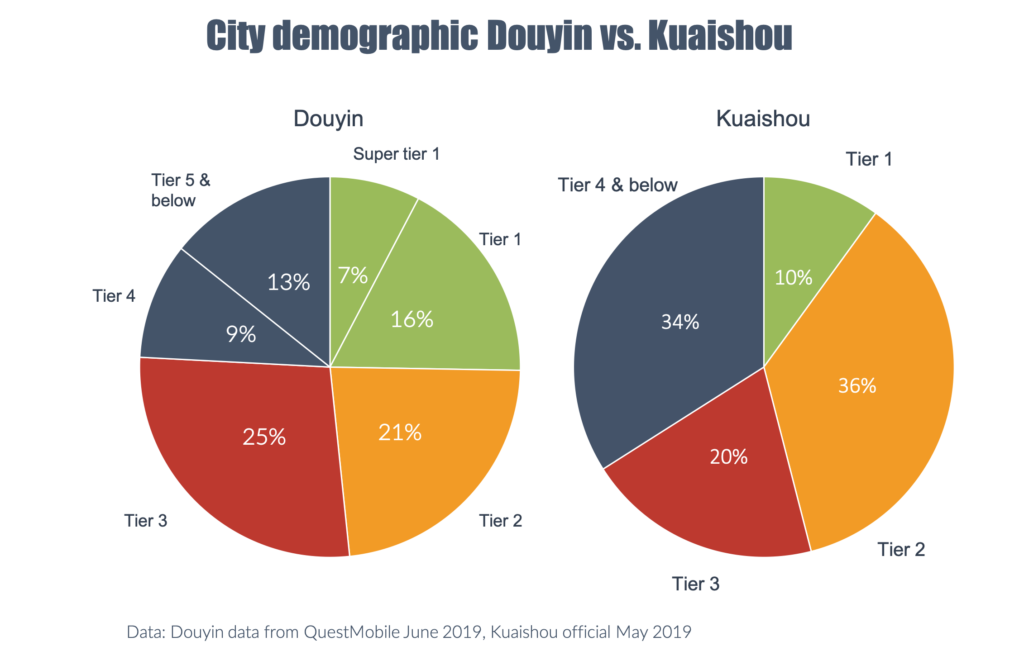
First things first: The Setup
I started by trying to figure out the easiest way to actually get the data. I knew I wasn’t going to build a full-blown crawler from scratch. That’s way too much effort. Instead, I hunted around for existing APIs and libraries. There are some unofficial APIs floating around, but they’re often unreliable and kinda sketchy. So, I ended up leaning heavily on Python with libraries like requests and BeautifulSoup to scrape the web versions (yeah, I know, not ideal, but it worked for my small-scale thing).
Douyin Diving
- The Initial Scrape: I focused on scraping hashtag pages related to South China – think specific cities like Guangzhou, Shenzhen, maybe even some broader terms like “粤语” (Cantonese). The HTML was a mess, as expected. I had to spend a bunch of time figuring out the structure and identifying the right elements to grab (video descriptions, usernames, view counts, etc.).
- Dealing with Dynamic Content: Douyin loads a lot of content dynamically, which meant I couldn’t just rely on simple
requests. I had to use something likeseleniumwith a headless browser to render the JavaScript and get the full page content. Pain in the butt, but necessary. - Data Cleaning: Once I had the raw data, it was filthy. Encoding issues, weird characters, inconsistent formatting – you name it. I spent a solid chunk of time cleaning it up with regular expressions and string manipulation in Python. Seriously, data cleaning is like 80% of the job.
Kuaishou Kickoff
- Similar Approach, Different Challenges: Kuaishou’s structure was different from Douyin, so I had to adapt my scraping code. More HTML parsing, more figuring out which elements held the important stuff.
- Rate Limiting: Both platforms were pretty sensitive to scraping. I got blocked a lot. I had to implement delays between requests and rotate user agents to avoid getting my IP address flagged. Still got blocked sometimes, though. It’s a constant cat-and-mouse game.
- More Data Cleaning! Yep, even more cleaning. Different platform, different types of mess.
South China Focus: Tagging and Filtering

This was the tricky part. How do you actually identify content that’s about South China? Just scraping hashtags wasn’t enough. I needed to analyze the video descriptions and potentially even the video content itself (which I didn’t have the time or resources for). I ended up using a combination of approaches:
- Keyword Matching: I created a list of keywords related to South China – city names, local dialects, famous landmarks, popular foods, etc. Then, I searched the video descriptions for these keywords.
- Location Data (Limited): Some videos had location data associated with them. I tried to use this to filter for videos that were actually in South China. This was unreliable, though, as not all videos had location information.
- Manual Review (Ugh): Honestly, I had to manually review a sample of the data to make sure my filters were working correctly. This was time-consuming, but it helped me identify and fix errors in my keyword lists and scraping logic.
Analyzing the Trends
Once I had a (relatively) clean dataset, I could start looking for trends. I used Python with libraries like pandas, matplotlib, and seaborn to do some basic analysis.
- Popular Hashtags: Which hashtags were most frequently used in South China-related videos? This gave me a sense of what topics were trending.
- Content Categories: What types of videos were most popular (e.g., food vlogs, travel videos, comedy sketches)? I tried to categorize the videos based on their descriptions and content.
- User Engagement: How many views, likes, and comments were South China-related videos getting? This helped me understand which types of content were resonating with audiences.
The (Messy) Results
The results were interesting, but definitely not conclusive. I found that:
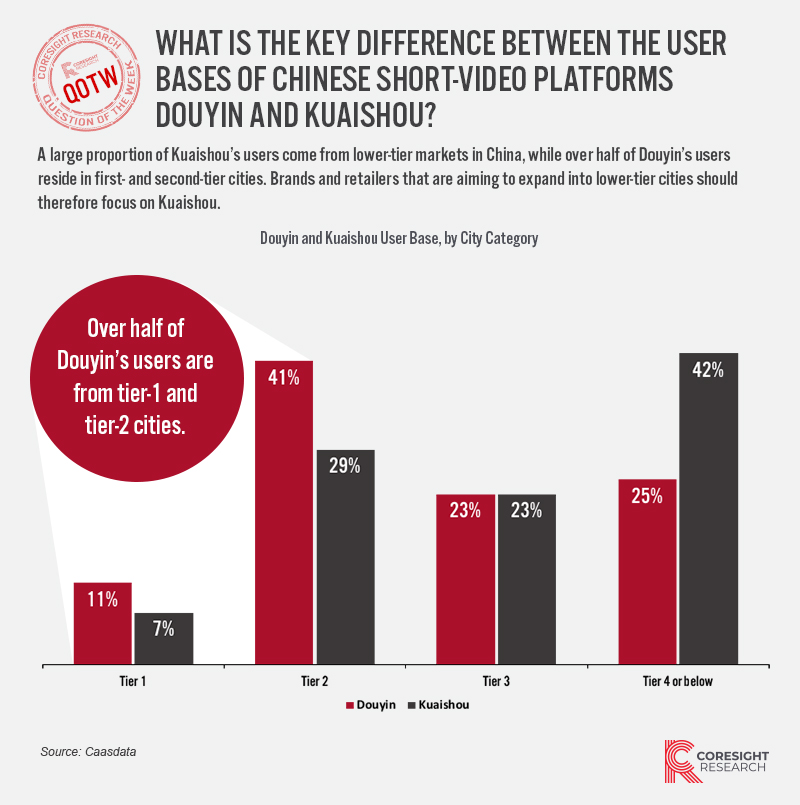
- Food-related content was hugely popular, especially videos showcasing local Cantonese cuisine.
- Travel videos featuring South China’s scenic spots were also common.
- There was a lot of content promoting local businesses and products.
- The overall tone of the content was generally positive and upbeat.
Lessons Learned
This whole thing was a learning experience. Here’s what I took away:
- Web scraping is hard work, especially when dealing with dynamic content and anti-scraping measures.
- Data cleaning is even harder.
- Analyzing unstructured data is challenging, but it can reveal interesting insights.
- I need to find better ways to automate the process of identifying and categorizing content. Maybe some NLP techniques next time?
Where to Go Next?
If I were to continue this project, I’d want to:
- Develop a more robust and reliable scraping system.
- Use more sophisticated NLP techniques to analyze the video descriptions and extract more meaningful information.
- Explore the use of computer vision to analyze the video content itself.
- Scale up the analysis to cover a larger dataset and a longer time period.
Anyway, that’s my story. It was a fun little project, even though it was a bit of a grind at times. Hopefully, this gives you some ideas if you’re thinking about doing something similar. Good luck, and happy scraping!
